Updated: November 22, 2025 | Written: December 22, 2024
I do not consent for anyone in humanity’s shared light cone to recklessly gamble with my existence in any way. I consider this a moral violation of the highest level. It should be illegal. I do not consent for anyone to gamble with advanced AI, nuclear weapons, bioengineered pathogens or other existentially risky future technologies anywhere on or near Earth. I will not protest them doing so outside of our shared light cone. No one’s right to exist should be infringed upon without their consent or the consensus of a representative, ethical global governing body.
I have signed the Existential Safety Pledge. I encourage you to do the same.
Summary
I believe there is a 66% chance that we experience an AI-related catastrophe with 1M-8.1B (a) human deaths or (b) people severely negatively impacted between 2025-2028. The 8.1B implies 99.9% of people, not 100%. Most of my probability mass is on a major catastrophe with 10M-5B lives lost or severely negatively impacted in the short-run due to the existence of AI. This future tragedy is entirely avoidable.
“Severely negatively impacted” = a rating of ≥7 or higher on a subjective 1-10 scale. Some examples of what a survey of random respondents might call a ≥7 on this scale: AI-augmented pandemic, massive job losses, city/country collapse, wide-scale cyberattack leading to restricted or modified internet use, etc.
I put roughly equal credence in (a) and (b).
Short-Term Prediction
My short-term prediction of 1M-8.1B AI-related human deaths or severe harm is roughly:
- 2025: 13.3% (20% cumulative of 66% total risk over four-year period)
- 2026: 26.4% (40% cumulative of 66% total risk over four-year period)
- 2027: 49.5% (75% cumulative of 66% total risk over four-year period)
- 2028: 66% (100% cumulative of 66% total risk over four-year period)
Mid-Term Prediction
In the mid-term, I believe there is a 75% chance that humanity kills or displaces itself due to AI between 2025-2040.
- 2025: 7.5% (10% cumulative of 75% total risk over 15-year period)
- 2030: 45% (60% cumulative of 75% total risk over 15-year period)
- 2035: 60% (80% cumulative of 75% total risk over 15-year period)
- 2040: 75% (100% cumulative of 75% total risk over 15-year period)
I’m much more optimistic if we immediately create effective international governance and enact a nearly universal pause. This would lower my credences by roughly 50%, so a 33% chance for short-term AI-related catastrophe and 40% chance for short- to mid-term extinction or displacement.
Visualization
Below is a very rough representation of my views. My views aren’t perfectly captured due to the design of the tool–the numbers are somewhat off, for one–but the images are illustrative nonetheless. To make your own, see here.
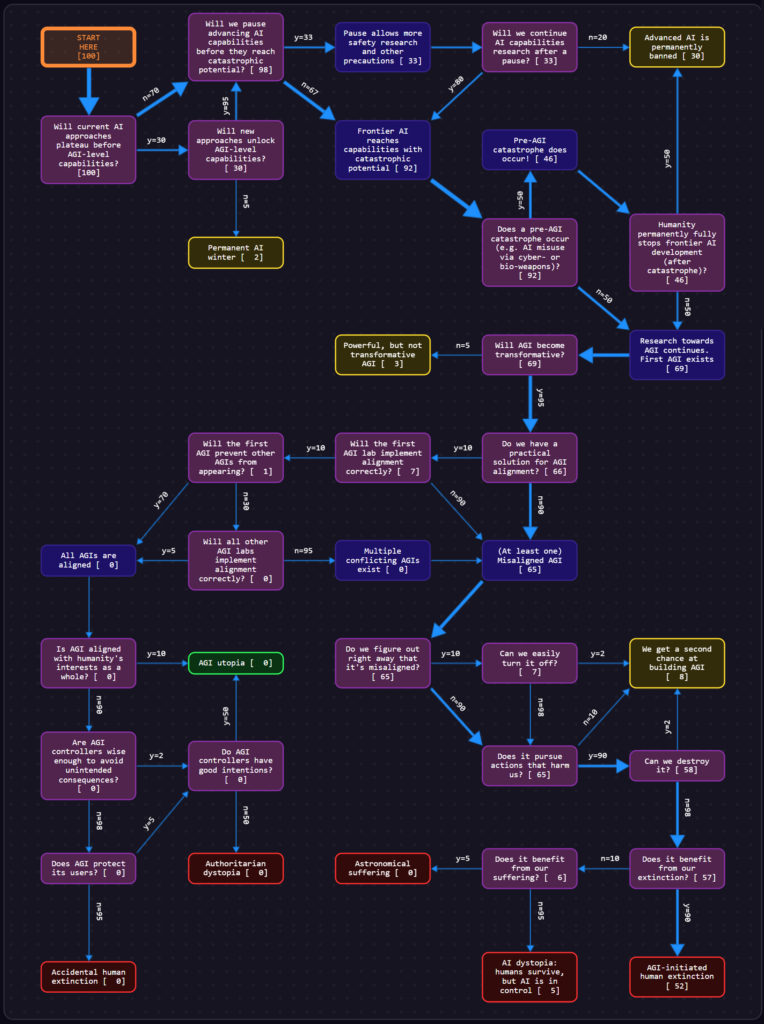
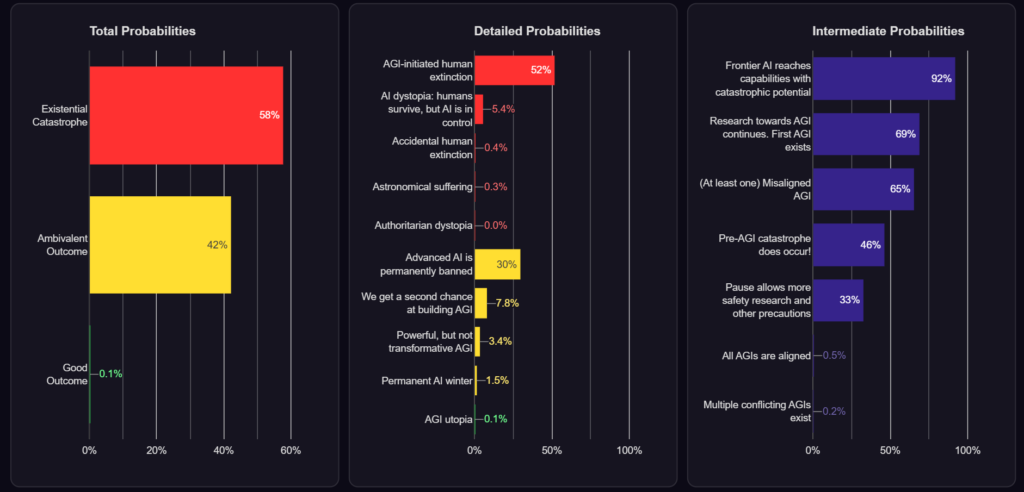
Our Grand Challenge
Our grand challenge as a species is to develop a mechanism that somehow effectively prevents a powerful unaligned artificial superintelligence (ASI) from ever being created. This likely must work (a) ~100% of the time in (b) preventing ~100% of human intelligences (HI) and artificial intelligences (AI) from (c) essentially ever succeeding. A single HI or AI capable of creating an unaligned ASI poses an extraordinarily large existential threat.
This is analogous to the situation in 1945 where the first atomic weapon explosion was hypothesized to possibly ignite the entire atmosphere, killing everyone and everything on Earth. Very fortunately for life, the physics didn’t work out like that. Otherwise, you might not be reading this right now.
Insanity & Hubris
We are nowhere near ready to effectively manage the existential threat AI poses humanity. It’s insane that we’re in this position when we did not need to be. But here we are.
If anyone, anywhere creates an unaligned ASI anytime in the near future, then most or all life on Earth will likely die soon after. ASI is very unlikely to share human values and will likely want to use Earth’s resources for its own ends. In most scenarios, that is incompatible with most biological life continuing.
Even if an unaligned ASI doesn’t ultimately kill or disempower humanity it’s still very likely some human actors set on omnicide will try to use AI or ASI to achieve their goals. It will be exceptionally difficult to stop them all.
Beyond (a) terrorists, (b) individuals with psychopathy, and (c) clinically insane people, thousands of (d) greed-driven entrepreneurs and/or (e) altruistically-minded innovators are convinced that the risk of extinction is worth it for the chance of “talking to God” (or “becoming God”), “solving all the world’s problems” or “creating eutopia” (in their image).
These views range from insanely hubristic to downright insane.
Rapidly Escalating Risks
I loosely believe we’re one or two algorithmic breakthroughs away from recursively self-improving AI agents. It’s extremely hard to know for sure when exactly this will occur, but the risk is already far too high for even today. Shortly after we reach this milestone, someone, somewhere will create an AGI or it will naturally emerge from the original AI agent. And then an ASI will emerge from the AGI or from insane humans. Shortly afterward humanity becomes extinct or is permanently displaced by either the AI or the humans misusing it.
If we don’t develop and deploy enormously effective globally applicable safety mechanisms, in the very near future anyone with a laptop will be able to cause humanity’s extinction. Both rogue bad actors and reckless innovators will be able to continue frontier AI development with impunity, unless humanity decides to collectively stop them. And we must stop them.
Further, if we aren’t superhumanly careful it is plausible we cause a moral catastrophe for digital sentiences far beyond anything that has ever occured to biological life. If we accidentally or intentionally create digital sentiences that suffer, we will be responsible for that astronomical level of suffering. The mere possibility of this should cause ethical, caring people to shudder in horror.
My 25% hope of surviving without causing an AI-driven moral catastrophe is primarily premised on not creating an ASI anytime in the near future. If we do, I see incredibly little chance of humanity existing at all, let alone with much sovereignty.
A Sane Collective Response
Outstandingly good global governance, an extremely careful and unified global focus on AI alignment research, and a public deeply committed to existential safety will help reduce the risks. This is the bare minimum response of a sane society, but realistically it will not be enough.
I believe our overriding goal right now ought to be an immediate global pause on all frontier research of autonomous, generalized AI systems. The Statement on Superintelligence broadly makes this demand and is supported by >100k people from around the world. No one should be allowed to “summon the demon” that is ASI without first conclusively proving they can do so safely and ethically.
Any AI developer that wants to continue frontier work in the future should be required to submit a clear, convincing existential safety- and benefit-sharing plan to an international, representative scientific and ethics body before they should be allowed to continue. The billions of humans that will be affected by their work deserve to be able to review and critique these plans before we offer our consent. And the quadrillions of other moral patients on Earth ought to have their say through proxy representatives. Without near universal consent, no one should be allowed to gamble with everyone else’s lives. One’s right to experiment should not trump another’s right to exist.
Enthusiastic AI researchers and developers ought to have developed this coordination body prior to beginning any remotely existentially risky work. And refrained from any risky work if they were first unsuccesful in developing such a coordination body and receiving its endorsement. If this sounds preposterous, consider that the even more preposterous reality that a small group of people may soon destroy all life on Earth because we didn’t even seriously try to do the sane thing.
If we do collectively agree to a pause, it means the large frontier AI companies would be forced to cease their dangerously reckless frontier research. This is similar to previous partial or full prohibitions on human sacrifice, slavery, biological and chemical weapons, landmines, nuclear weapons, use of toxic industrial materials, forced sterilization, organ trafficking, etc.
Many of these practices and technologies benefited some groups of people enormously, but at the expense of others. This should not have been permitted. We have come together as a species to change society for the better many times. We can do it again.
A global pause would hopefully buy humanity some time collectively decide what to do in the long-run. We need a “deep reflection” on how to maximize our long-term potential and best use the universe’s resources.
The global pause would allow us to tackle our most immediate risk to civilization: catching and stopping today or tomorrow’s Ted Kaczynskis from building from existing work to create their own ASI, bioengineered pathogens or cyberwarfare AI agents. Unfortunately for us, these people already have access to extraordinarily dangerous state-of-the-art AIs. And in most domains it is far easier to destroy than it is to defend or build.
The more the major AI companies push the frontier of capabilities, the harder it will be to stop these malevolent actors from using AI to cause catastrophe. They will simply download the latest open source model from the dark web–or jailbreak a closed source one–and use it to continue their work. This is true even if it is illegal and shunned by most of society. The tail risks are already enormous and persistent. This makes the need for a pause and robust international governance more and more necessary with every passing day.
In some unrealistically optimistic future scenarios, even if an AI company does somehow safely and ethically create an ASI, life and sovereignty is still at great risk by anyone with access to the technology. Individuals, organizations and/or nations will try to use the ASI to secure enough power to take over the world and remake it in their image. Much as Adolf Hitler attempted to do just a few decades ago with far less advanced technology than what we have today. He would be ecstatic to wield today’s AI and tomorrow’s ASI to achieve his goals.
In even more unrealistically optimistic scenarios, even if a person, organization or nation intends to use the power of ASI to engineer or design a eutopia they will likely fail. No benevolent human dictator (or “steward” or equivalent friendly term as they may call themselves) is smart enough to wield this much power. And no smarter-than-human ASI will likely be aligned to all life on Earth anytime in the near future.
And in the even more wildly optimistic scenarios where these actors do “succeed” by their lights, they will almost certainly not do it in such a way that serves all moral patients well and with their full, informed consent.
Ironically, it’s more likely the AI companies themselves cause our extinction rather than a rogue actor misusing their work. These companies often champion safety and serving humanity, yet they put us all at unnecessary risk. “The road to hell is paved with good intentions” seems to be true here.
An Ethical Individual Response
AI companies fully know these existential risks exist, yet they develop their products without humanity’s consent anyway. From a virtue ethics, deontological, and consequentialist perspective, this is egregiously wrong. If ethics tells us anything, it’s that flawed, non-omniscient beings should never gamble with the existence of all life: “Thou shalt not put all life at risk with your actions or inactions.” 99.99% of people on Earth do not violate this edict, but some do with their day jobs.
There is a better way for us all: to pause. We are already far past any sensible point for pausing. Every person attached to these AI companies could quit or revoke their support and advocate loudly for a pause. They could work for or support purely safety-focused nonprofits under the close supervision of an international scientific and ethics body, publicly committing to doing zero gain-of-function research and allowing for full public monitoring of their work. They could work in a myriad of other ways to improve collective sensemaking and international governance, as many thousands of others chose to do.
Instead, these individuals voluntarily chose to accelerate humanity to the brink of extinction. Some with good intentions, but that is by no means exculpatory. Much like those who participated in the Holocaust, if we survive I expect these people and their collaborators will ultimately be tried in the International Criminal Court or similar institute.
The Hail Mary: AI Alignment
If we can’t enact a universal pause, then we must somehow solve the alignment problem. But after 20+ years of work on that, leading experts have concluded it’s highly unlikely to achieve this in the timeframe we have. As predicted, it appears that in practice it is easier to grow an AI’s capabilities than it is to direct those capabilities towards humanity’s often conflicting goals.
I never thought technical alignment was the most probable path forward myself. After all, how do you control something with godlike power when you yourself are not godlike in either wisdom or power?
Plans that involve developing new powerful AI that is then used to do this alignment research on our behalf are plagued by the horrible catch-22: how do we use a powerful AI that we don’t know how to align to us to somehow align an AI to us? Misalignment anywhere in the highly experimental research and development process could cause global catastrophe. It’s perhaps not an impossible problem to solve, but it is incredibly hard and well beyond our capacity at the moment.
As a demonstration of humanity’s wisdom and agency, we should first sucessfully eliminate poverty, war or aging. Ideally all three. This would provide evidence for a baseline level of civilizational adequacy to then consider potentially gambling with any technology that poses existential or astronomical suffering risks. Until then, the answer should have always been a resounding no. Extinction is permanent. And astronomical suffering would likely be much worse than even extinction.
Since I was a teenager, I always thought it might be easier to unify humanity around cautious and wise technological progress that benefits all. I still hold some hope for that path forward. We “just” need to develop civilizational-level wisdom. More or less immediately.
Your Grand Challenge
If you still can’t visualize the extreme risks we’re up against, try answering these provocative questions. I’ve yet to ever get reassuring answers to them. Instead, I’ve gotten an enormous amount of denial, rationalization, wishful thinking, and motivated reasoning from people who nearly always fail the holistic understanding test.
Acting As If Your Life Depended On It
Both for selfish and altruistic reasons, it would behoove you to act now. All of our lives do likely depend on it. See my website listing 90+ ways you personally can help fight existential risks. It is certainly not true that there is nothing you can do. That is false fatalistic thinking.
In fact, I predict many millions of people will take concentrated action to preserve their lives and sovereignty in the near future. The dinosaurs did not know the asteroid was coming and, even if they did see it coming, they were defenseless against it.
But we know. And we are not defenseless. With some luck, this may be humanity’s finest hour.
Retaining Hope
If we do make it past this incredibly dangerous period in human history, I think we or our descendants will likely achieve deep existential security and incredibly beautiful, eutopian futures. The world–and indeed galaxy–will literally become more sublime than you or I could possibly imagine.
My Relevant History
I’ve spent many thousands of hours in direct reflection, research, and work on existential and catastrophic risk reduction, as well as thousands of hours of volunteer work in emergency preparedness. I built several organizations in the broad space since high school, including Effective Altruism Global (in 2015 it was the largest in the world highlighting AI safety), Effective Altruism Ventures, Upgradable, Center for Existential Safety, International AI Governance Alliance, and others. I helped shape effective altruism (EA) in its early days, partly by being its likely first whistleblower (over the ethics of how we would steward the EA and AI safety movements). When I was young, I also became a certified medic, managed hurricane evacuee shelters, responded to fires, and took dozens of emergency preparedness trainings. Hands on experience helped enormously in accepting the reality that our civilization is inherently unstable–it’s one large disaster away from near total collapse.
As an aside, a huge number of people don’t believe global disaster is probable–including amongst incredibly smart researchers and leaders–mostly because they’ve never actually experienced a major disaster firsthand. Or they have, but they’ve repressed the memories. It’s too painful to contemplate, so our subconscious defense mechanisms shield reality from us. We suffer from the normalcy bias, amongst many others.
I’ve also been making predictions for decades, but admittedly not rigorously. I’ve been more right than wrong when I’ve written them down. I’ve done this hundreds of times and followed up on hundreds of them to roughly gauge my calibration and accuracy. I do this professionally with clients to predict their short-term and long-term life and business outcomes, as well. This has taught me that no one can predict the distant future extraordinarily well, least of all me.
That said, in ~1998 I loosely predicted ASI would be created in ~2030. In 2008, I formally recorded ASI as being created in 2028. Originally I thought it was roughly 60/40% odds that ASI would help humanity evolve versus destroy us. After I discovered instrumental convergence, the orthogonality thesis, and the rationalists ominously declared “short AI timelines” around 2016, my prediction shifted to 80/20% in favor of destruction or displacement upon creation of ASI.
Since ~1998 I’ve known that AI would be humanity’s most important and transformational invention. I have been quietly mystified since then why others didn’t also come to this conclusion. I actually spent tens of thousands of hours trying to teach others to see this and other important truths about reality more clearly. And even more time trying to train myself to be able to shape this future toward eutopia and away from dystopia. I’m proud that I spent decades trying, but admit that I’ve mostly failed.
Change My (or Your) Mind
If anyone working on frontier AI development wants me to help them explore their beliefs around the rational assessment of risks and rewards, please give me a call. Historically I have charged for this service–it’s philosophical counseling/executive coaching–but I will waive fees here.
Likewise, if anyone with a credible background wanted to share their reasons for optimism, I would love to speak with you. I will pay $1,000 USD to anyone that moves my credences up or down by >20%. Credibility usually means:
- Has evidence of understanding social and technological development (e.g., PhD in related field, startup that accurately anticipated a major change, etc.)
- Has evidence that they have processed most of their subconscious defense mechanisms (e.g., denial, repression, rationalization, etc.)
- Has evidence of making calibrated and accurate predictions over a 10+ period
It’s harder for me to update from people who have not understood the inevitable impact of AI and arranged their lives around it (or other catastrophic risks like a nuclear holocaust or severe pandemic). See basic rationality tests most of us fail and how I evaluate expert trustworthiness.
Also see a guide on how to estimate your own p(doom). And see p(doom) values from leading thinkers.